

Two years ago we started implementing a corporate loans application for one of the largest financial institutes of Russia and Eastern Europe. Since then the system has grown to the size of more than 32k rules and is now being developed by three independent teams producing about 4k check-ins per week.
Working on this project was a great experience for everyone in our team as it was the largest and the most challenging Pega project we had ever had before, and we’ve learned many lessons.
One of the important things we’ve found was that despite the ‘no coding’ paradigm unit testing on complex Pega project is as much important as on any other software development project.
One day something went wrong
The problem occurred unexpectedly. We were releasing a critical milestone version with numerous complex integrations with back-end systems. System testing identified a number of defects in integration scenarios. All teams involved had two weeks left to fix their applications.
At first it seemed to be a routine procedure:
- Identify failed integration scenarios.
- Identify conflicts between ‘our’ and ‘their’ integration specifications that caused failures.
- Agree on each case who should fix integration specification and implementation: ‘we’ or ‘they’.
- Fix and release new version of each application.
The list of scenarios to be changed on ‘our’ side was not short, but it didn’t look frightening. It took the whole team about a week to rework integration layer of our application.
We were sure that we would deliver our application on time, because no one could ever imagine that it would take another two weeks and numerous releases to QA to fix all the issues occurred after those significant changes we made. As a result we failed to satisfy customer expectation of getting application released on time.
Analyzing the problem
We analyzed this painful failure and identified the following core reasons:
- Due to high application complexity there was no way to verify that changes introduced at one place didn’t break something in absolutely different part of application. This led to a high rate of regression defects.
- Components description that we used to keep on project wiki was detached from ‘code’ and was often outdated and didn’t describe specific behavior of rules under certain circumstances. So developers using existing component didn’t have enough information to handle all the exceptions and specific results returned by a component.
- System architects tend to handle only primary scenarios, leaving alternate scenarios such as special cases, error handling and data absence unimplemented.
Considering our expertise in Java we were aware that similar problems in Java projects are usually solved by using such practices as unit testing, test-driven development and continuous integration. So, introducing these practices into our project seemed just natural.
Unit testing design
We decided to start with creating automated unit tests for integration layer as it was the most complicated area of our application producing up to 80% of bugs.
Typical integration component in our application consisted of six major elements:
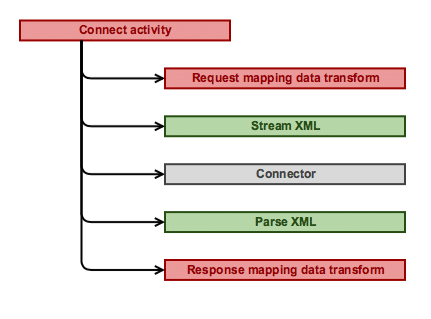 Connect activity – the main element that orchestrated all other elements and was the entry point to invoke the integration from flow, flow action post processing, data page source, etc.
Connect activity – the main element that orchestrated all other elements and was the entry point to invoke the integration from flow, flow action post processing, data page source, etc.- Request mapping data transform mapped request from business model.
- Stream XML rule serialized request from integration model to XML.
- Connector rule communicated with external system via appropriate protocol.
- Parse XML rule deserialized response from XML to integration model.
- Response mapping data transform mapped response to business model.
Stream and parse XML rules were usually generated by Connector and Metadata Wizard along with integration data model. Connector rule was intentionally left thin (almost transparent) by moving most logic to connect activity (invoking appropriate stream/parse rules, error handing, etc). The greatest number of defects were produced by connect activity, request and response mapping data transforms because those elements contained the major logic of any integration component.
Considering integration layer architecture described we intended to create a test suite for each integration point consisting of:
- Connect activity isolated test to cover integration logic including exceptional cases.
- Request mapping data transform isolated test.
- Response mapping data transform isolated test.
- Integration component overall test to check that output XML is generated correctly according to requirements as well as input XML is processed correctly. This test ideally should not invoke external system for isolation and performance reasons.
Elements on the diagram are colored according to ‘bug capacity’ and thus proposed test coverage: red – error-prone elements that should be tested in isolation for best coverage (unit test), green – less error-prone elements that may be covered enough by testing in integration with other elements (inner component test), gray – elements unlikely to produce a bug that could be left uncovered by a test suite.
Pega-style unit testing
The first thing we tried was Pega Test Cases. While it proved to be useful in simple applications, it appeared to have a major restriction for enterprise-scale projects: one cannot control rule dependencies isolation in tests.
In our case it meant that we wouldn’t be able to implement isolated testing not only for connect activity but also for data transforms as they could use data pages that were referencing other rules (activity, report definitions, other data transforms, etc.) as their data sources. Thus, Pega unit testing was applicable for implementing only one of four test types we intended to create for each integration point – the integration component isolated test. Moreover, this was possible only for integration components and only thanks to Integration Simulation mechanism which in turn raised additional flexibility and maintenance issues.
The restriction described above wasn’t the only concern we had about Pega unit testing capabilities:
- There was no convenient way to manage test setup and assertions until Pega 7.2 came (we were using Pega 7.1.8 at that moment). The side effect of this restriction was that all test cases had to be recreated after significant rule changes.
- Low reusability of testing artifacts (even now, considering significant improvements to unit testing introduced in Pega 7.2, there is no way to split complex assertions into separate blocks and reuse them in multiple test cases).
- There is no way to create complex test cases calling several rules in sequence, then asserting combined result.
- Pega provides test case support for limited number of rule types: activity, decision table, decision tree, flow, service SOAP (with some effort you can also create tests for data transforms and data pages).
Given aforementioned restrictions and concerns we definitely needed another approach to automated testing.
Research & Development
We started by gathering a strong team of Pega and Java project veterans. Through brainstorms and feedback from project teams we crystallized main features of what we needed:
- Control rule dependency isolation.
- Mock and stub rules like Java developers do.
- Break down complex tests into smaller blocks and reuse them if needed.
- Run tests in any decent build server.
After several months of prototyping and implementation alpha version was released to be piloted on a small subset of rulebase. The pilot was a success as tests immediately started bringing value: finding several subtle defects at the time of writing them and later preventing new regression defects from moving further.
After almost a year, most our projects adopted new unit testing approach. The instrument we’ve created required a name, so it emerged: Ninja.
Ninja-style unit testing
Ninja provides client-side Java library that allows you to write JUnit tests for your rules, so unit testing Pega application becomes as easy as in Java.
What makes Ninja so convenient for testing Pega applications?
First of all, Ninja encrypts and securely stores your credentials and uses them to log into Pega and run tests on your behalf. This means that you can run a test over a checked-out version of a rule.
Second, Ninja uses the same session for consequent test runs, it means that you can identify a Requestor used by Ninja and trace it to see what’s going on when a rule being tested is invoked.
Ninja allows you to setup environment easily and precisely.
You can mock rules invoked directly or indirectly by a rule being tested. This enables you to test your rules in a manageable isolation.
You can invoke in your test scenario almost everything that has behavior in Pega 7 (unit testing is not suitable for long-running processing and GUI that’s why Ninja doesn’t support Flows, Flow Actions, Sections and other GUI-related rules).
You can assert test results comprehensively.
For more examples please visit Ninja cookbook at GitHub.
With the help of Ninja we covered major integration scenarios with unit testing:
- We tested connect activities in isolation by mocking other rules, this helped us to focus on integration logic and verify all branches including exceptional cases.
- Data mappings were exhaustively verified by testing data transforms in isolation with mocking everything they were invoking directly or indirectly (functions, various decision rules, data sources for data pages involved, etc).
- We mocked connect rules to prevent integration component overall test from invoking external systems and to verify XML generated by a component.
While creating our unit test base we identified a number of commonly used setup routines and assertions and extracted them as a reusable library. This helped us to reduce costs of covering the application with unit tests.
Gained confidence
At the time of writing, our loan application has several branches: bug fix for production and several release scopes. Every branch is covered by unit tests which evolve just as application does. Tests are stored in VCS and are branched as well. Production branch has 350 tests, whereas last release branch up to 500.
Unit tests are run by our build server for each branch individually every 30 minutes. It means that our team receives application health status every 30 minutes and can react timely on bugs introduced by recent changes.
Ninja allows faster delivery of higher quality product due to:
- Less Dev-to-QA circles as majority of bugs are caught on Dev and fixed right away.
- Less bugs in production due to more exhaustive testing by QA team who doesn’t have to deal with trivial bugs blocking test scenarios.
To be continued…
Our experience told us that unit testing was not the only area of Pega platform developer tools that had substantial restrictions in comparison with modern tools available for Java and other ‘traditional’ application development platforms.
Considering feedback from project teams and brainstorms we identified features to be added to Ninja next:
- Rule refactoring
- Code analysis
- Code review
- Release automation
- Continuous delivery pipeline
We believe that these features will make Ninja a comprehensive toolchain for adopting DevOps in Pega projects.